Building AI Agents

A Phased Architecture for Complex CoA Phased Architecture for Complex Context Understanding
AI agents are no longer just “LLM + prompt”.
Real-world agents must reason, remember, act, and adapt across long-running tasks, multiple systems, and evolving context.
This article presents a phased architecture for building scalable AI agents — from naive prompt-based systems to production-grade agent platforms using vector databases, graph databases, and structured context management.
Phase 1: Prompt-Centric Agents (The Native Phase)
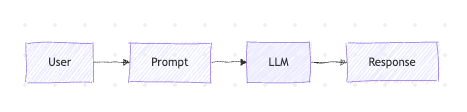
At the earliest stage, an AI agent is little more than a single LLM call.
characteristic of these kind of agents stataless, no memory, no tools, no persistence. so when it's works ? chatbots, one-shot tasks, simple transformations.
Way of this architecture is not good to solve problems of real life is when you need long-term understanding, no task decomposition.
This phase collapses as soon as tasks span multiple steps or sessions.
Phase 2: Tool-Using Agents (LangChain-Style)
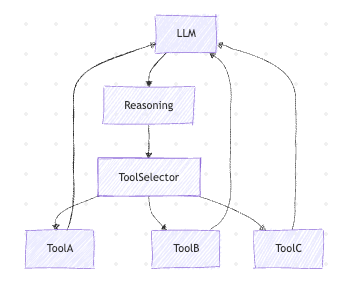
Once agents need to do things, not just talk, tools become mandatory. Frameworks like LangChain and LangGraph help orchestrate this.
Typical tools
- APIs
- Databases
- File systems
- Code execution
- Search engines
What LangChain actually gives you
- Tool abstraction
- Agent execution loops
- Prompt templates
- Memory interfaces (basic)
New problems
- Tool hallucination
- Weak planning
- No real memory
- Context window pressure
Agents can now act, but they still can’t remember properly.
Phase 3: Vector Databases (Semantic Memory)
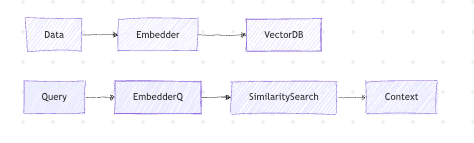
LLMs don’t store memory — they reconstruct meaning. Vector databases give agents semantic recall.
Common vector databases Qdrant, Pinecone, Chroma...
What gets stored
- Conversations
- Documents
- Observations
- Logs
- Summaries
Strengths
- Semantic similarity
- Token-efficient
- Scales well
Weaknesses
- No structure
- No causality
- No explicit relationships
Vector databases answer:
“What is similar to this?”
They do not answer:
“How is this connected?”
Phase 4: Graph Databases (Structural Context)
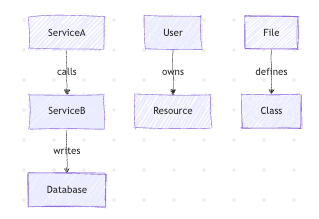
As agent intelligence grows, context becomes relational, not textual.
Examples
- Service dependencies
- Network topology
- Code relationships
- Ownership models
- Event causality
This is graph-shaped knowledge.
Common graph databases
- Neo4j
- ArangoDB
- Amazon Neptune
- Memgraph
What graphs enable
- Multi-hop reasoning
- Dependency analysis
- Root-cause detection
- Explicit meaning
Vector DB = semantic similarity
Graph DB = explicit structure
They are complementary.
Phase 5: Hybrid Memory (Vector + Graph + State)
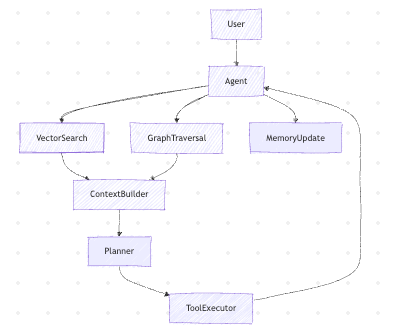
Production agents never rely on a single memory type.
Memory layers
| Layer | Purpose |
|---|---|
| Prompt Context | Immediate reasoning |
| Short-term State | Current task |
| Vector Memory | Semantic recall |
| Graph Memory | Structural knowledge |
| Source DBs | Ground truth |
This is where agents stop feeling like chatbots and start behaving like systems.
Phase 6: Context Management & Compression
This is the hardest problem in agent engineering.
Context is expensive, limited, and fragile.
Key challenges
- What to keep
- What to summarize
- What to forget
- What to externalize
Techniques
- Hierarchical summaries
- Importance scoring
- Time-based decay
- Task-scoped memory
- Event-driven persistence
Bad context management causes:
- Hallucinations
- Drift
- Token explosions
Good context management feels like:
“The agent understands the system.”
Phase 7: Agent-Oriented Architecture (Production)
At scale, agents become services, not scripts.
Production components
- Agent Gateway
- Orchestrator
- Tool services
- Memory services
- AuthN / AuthZ
- Observability
- Safety layers
High-level architecture
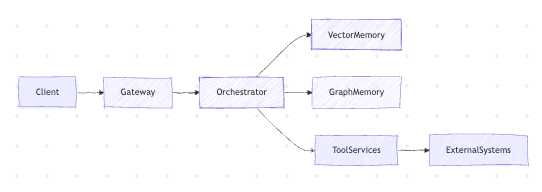
At this stage:
- Frameworks become optional
- Custom orchestration wins
- Determinism > creativity
Key Takeaways
- AI agents evolve in phases
- LangChain is a starting point, not a destination
- Vector databases handle semantic memory
- Graph databases handle structure and causality
- Real intelligence emerges from hybrid context
- Context management is the core engineering challenge
Design agents assuming they will grow — and you won’t need to rebuild everything later.
Agent Frameworks & Orchestration
LangChain
- https://github.com/langchain-ai/langchain
Why: Popular starting point for tool-using agents, memory abstractions, prompt templates.
LangGraph
- https://github.com/langchain-ai/langgraph
Why: State-machine / graph-based agent workflows, better control than classic agent loops.
AutoGen
- https://github.com/microsoft/autogen
Why: Multi-agent conversations, role-based agents, good for coordination patterns.
CrewAI
- https://github.com/joaomdmoura/crewAI
Why: Opinionated multi-agent task delegation, simple mental model.
Haystack
- https://github.com/deepset-ai/haystack
Why: Strong pipelines for retrieval-augmented generation (RAG), search-heavy agents.
Vector Databases
Qdrant
- https://github.com/qdrant/qdrant
Why: Fast, open-source, production-ready, excellent filtering support.
Weaviate
- https://github.com/weaviate/weaviate
Why: Schema-aware vector DB with hybrid (vector + keyword) search.
Milvus
- https://github.com/milvus-io/milvus
Why: Highly scalable vector database, used at large scale.
Chroma
- https://github.com/chroma-core/chroma
Why: Lightweight, local-first, great for prototyping and dev environments.
Graph Databases Structural & Relational Context
Neo4j
- https://github.com/neo4j/neo4j
Why: Industry standard graph DB, powerful traversal and query language (Cypher).
ArangoDB
- https://github.com/arangodb/arangodb
Why: Multi-model (graph + document + key-value), flexible for hybrid workloads.
Memgraph
- https://github.com/memgraph/memgraph
Why: In-memory graph DB optimized for real-time analytics.
Tooling & Function Execution
OpenAPI Tooling
- https://github.com/OpenAPITools/openapi-generator
Why: Generate typed clients for agent tool execution.
Temporal
- https://github.com/temporalio/temporal
Why: Durable workflows, retries, long-running agent tasks.
Dapr
- https://github.com/dapr/dapr
Why: Sidecar architecture for service-to-service calls, pub/sub, secrets.
Context Management & Memory Utilities
LlamaIndex
- https://github.com/run-llama/llama_index
Why: Advanced indexing, document chunking, retrieval strategies.
DSPy
- https://github.com/stanfordnlp/dspy
Why: Prompt optimization and declarative LLM pipelines.